2. Principles of Phonetics
Key Concepts
- Speaking uses biological structures evolved for other purposes
- A parametric description of an utterance attempts to preserve the continuous, smooth, asynchronous character of its articulation
- Phonology is concerned with discrete operations on abstract symbols, while Phonetics is concerned with continuous changes in articulator position and sound
- Phonetic transcription is best thought of as a simplified form of parametric description guided by language phonology
- Phonetic transcription is an invention of Phoneticians, it is not part of the process of speaking or listening
Learning Objectives
At the end of this topic the student should be able to:
- explain how speech is overlaid on biological systems used for other purposes
- list some instrumental methods for measuring and tracking articulation of speech
- contrast a parametric account of speech articulation with a segmental account
- explain the selection procedure behind the symbols found on the IPA alphabet
- discuss the status of phonetic transcription with respect to Phonetics and to Phonology
- contrast segmental with suprasegmental features of speech
- contrast linguistic with paralinguistic aspects of speech
Topics
- Biological basis of speech
We tend to use the term vocal tract as a name for the anatomical elements of the human body that produce speech. But strictly speaking there is no such thing, since there is no part of the apparatus used to produce speech which is only used for that purpose.
Physiologically, speech is an overlaid function, or to be more precise, a group of overlaid functions. It gets what service it can out of organs and functions, nervous and muscular, that have come into being and are maintained for very different ends than its own. [Sapir, 1921].
Sub-system Biological function Linguistic function Diaphragm, lungs, rib-cage Respiration Source of air-flow used to generate sounds Larynx Acting as a valve, coughing Phonation Velum Breathing through the nose, acting as a valve Production of nasal & nasalised sounds Tongue Eating, swallowing Changing acoustics of oral cavity, creating constrictions that generate turbulence, blocking and releasing air-flow causing bursts Teeth Biting, chewing Provide sharp edges for creating turbulence Lips Feeding, acting as valve, facial expression Changing acoustics of oral cavity, creating constriction that generates turbulence, blocking and releasing air-flow causing bursts Do humans have a biological specialisation for speech?
An interesting question is whether humans (compared to nonhuman primates) have any anatomical or physiological specialisation for speech. It turns out that there is still no convincing evidence of this. Structurally, the vocal organs are similar across primates. A past theory claimed that the larynx in humans is placed lower in the throat compared to other related animals so as to make a more flexible acoustic cavity between larynx and lips. However modern studies have shown that other animals, including chimpanzees, have similar larynx development to human infants.
Our hearing, likewise, seems very similar to the hearing of other mammals. There are differences in the sensitivity and frequency range of hearing across mammals, but these can be attributed to differences in the physical size of the hearing organs and evolutionary specialisation for detecting prey and/or predators (bats, for example have a specialised sensitivity to the frequencies used for echo-location).
It may be easy to say that our brains are different, but while there are many differences between the structure of human and nonhuman primate brains, these differences have yet to be uniquely associated with language.
If humans have any biological specialisation for speech then it is more likely to be found at the neuro-physiological level. The human variant of the FOXP2 gene seems to be necessary for the development of the neural circuitry that co-ordinates movements required for speech (among other things). This gene appears to be different in humans compared to chimpanzees and carrying an abnormal version of the gene leads to speech and language disorders.
- Tracking the articulation of speech
Folk wisdom has it that we use 72 different muscles in speaking. The number may be in doubt, but there are certainly a lot, see this list of muscles used in speech production.
When we seek to describe the planning and execution of speech we tend to focus on the movements of the articulators rather than the muscle movements behind them. This immediately reduces the problem to one of describing the position and movement of the vocal folds, the soft-palate, the back, front, sides and tip of the tongue, the lips and the jaw. That is, to the movement of 10-12 objects rather than 72.
Speaking requires co-ordinated movement of the articulators to achieve a desired acoustic result. The articulators move asynchronously but in a choreographed way. Their motion is rapid, precise and fluid, as can be seen on x-ray films of speaking.
A number of instruments have been developed for tracking and measuring the movements of the articulators during speaking. There are imaging methods apart from x-ray movies such as real-time magnetic resonance imaging (MRI) and ultrasound; and tracking systems such as electro-magnetic articulography (EMA) and electropalatography (EPG). Below is some output from EMA, the graphs represent the heights of small coils glued to some of the articulators of someone speaking "this was easy for us".
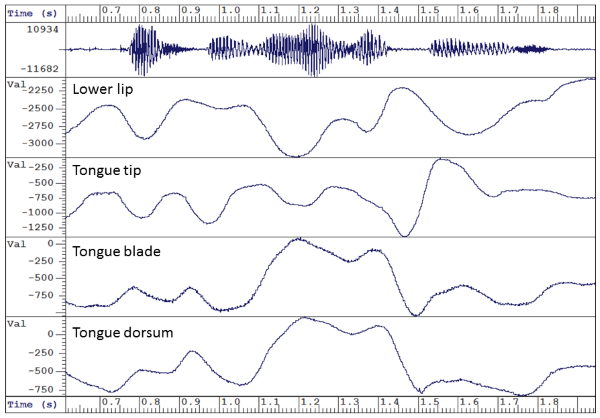
Imaging and tracking instruments confirm the smooth, asynchronous and co-ordinated movements of the articulators while speaking.
- From parametric to segmental accounts of speech
If we track the movement of any single articulator we see that it takes a smoothly-changing continuum of positions. If we attempt to track the position of the articulators for a given utterance then we obtain a parametric description of the speech. Consider this simplified diagram of some of the articulator movement over time in the production of a single word [image source: Laver 1994]:
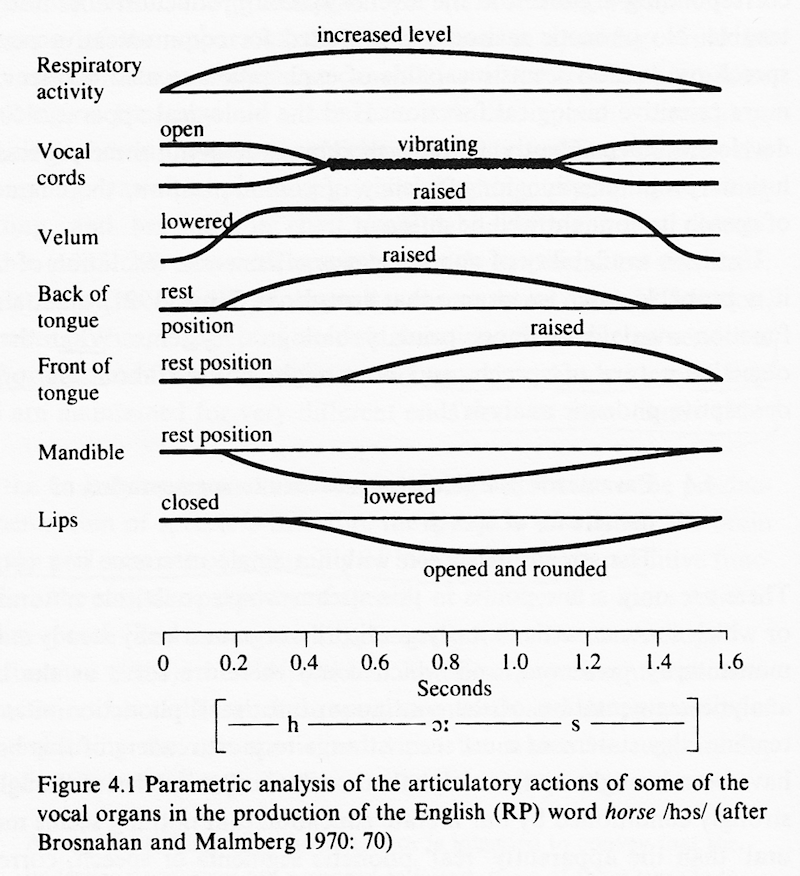
Even this schematised account hints at the complexity of parametric analysis. While parametric accounts of speaking may provide a more authentic description of articulation (see reading by Tench (1978)), the possible variations in articulator position, movement and timing make these formulations rather difficult to construct, analyse and exploit (imagine a diagram like this for every word in a dictionary). We need to think about how we can best simplify a parametric description into a more convenient formalism.
There are a number of possible simplification steps:
- Discretize the position of each articulator into a small number of levels. So that the soft palate for example, is only described as either open or closed. Or the lip shape is only described as either spread or rounded.
- Discretize the timing of each articulator movement, so that instead of a motion that continuously varies with time, we get instead a piecewise constant or "step function" account.
- Synchronize the timing of changes in each articulator across all articulators, so that the same time intervals describe piecewise constant sections of all articulators.
- Categorise the intervals using a small inventory of possible combinations of articulator positions.
- Symbolise the categories using a set of characters and diacritics.
The input to the process is a parametric account, the output is a symbolic, segmental account that we call a transcription.
An important question at this point is to ask what information is lost in the process of transcription? Or to put it another way what fidelity is required in our transcription such that no useful articulator movement is lost? Clearly we could use very fine levels of position, or many brief instants of time, or a large inventory of categories and symbols to achieve high fidelity, but this would add much complexity to the transcription.
Different criteria could be used to decide on how accurately we need to specify the articulator positions and articulatory time intervals:
- Articulatory criterion: might say choose enough levels and intervals such that each articulator position can be specified to within a given tolerance, say 1mm.
- Acoustic criterion: might say choose enough levels and intervals such that the sound generated by the articulation can be specified to within a given tolerance, say one decibel (1dB).
- Auditory criterion: might say choose enough levels and intervals such that the sound perceived by an average listener can be specified within a given auditory tolerance, say within the just-noticeable-difference (JND) for loudness, pitch or timbre.
- Phonological criterion: might say choose enough levels and intervals such that all articulations that act contrastively (i.e. give rise to different meanings in any world language) are assigned different categories and symbols.
You should not be surprised to hear that it is the last of these that has been adopted in practice. This key idea, that the fidelity of transcription should be just good enough to describe articulatory changes that lead to changes in meaning (in some language) is one of the principles underlying the alphabet of the International Phonetic Association.
The IPA is intended to be a set of symbols for representing all the possible sounds of the world's languages. The representation of these sounds uses a set or phonetic categories which describe how each sound is made. These categories define a number of natural classes of sounds that operate in phonological rules and historical sound changes. The symbols of the IPA are shorthand ways of indicating certain intersections of these categories. Thus [p] is a shorthand way of designating the intersection of the categories voiceless, bilabial, and plosive; [m] is the intersection of the categories voiced, bilabial, and nasal; and so on. The sounds that are represented by the symbols are primarily those that serve to distinguish one word from another in a language. [ Handbook of the IPA, 1999 ]
Relaxing the rules
It is interesting to speculate about what might happen if we had used different criteria for generating a segmental transcription from a parametric analysis. If we allow time intervals to operate asynchronously across the articulators (to remove the requirement that all articulators make a step change together) then we get a polysystemic account of phonetics, one in which planning is concerned with each articulator independently, and where phenomena can be accounted for on different timescales. The most famous practitioner of such ideas was J.R. Firth (who worked at UCL and SOAS) with his prosodic phonology.
Another approach would to be perform segmentation on the acoustic signal rather than the articulatory tracks to get a kind of "acoustic phonology", one that says that phonological categories are formed because of the auditory similarity of sound chunks. You might like to think about what problems might arise with this idea (hint: what if differences across repetitions of a lexical item are greater than the differences between lexical items?)
- From Phonology to Phonetics
We have presented phonetic transcription as an impoverished form of articulatory description: something that is not quite as good as a parametric description or an instrumental analysis while being a much more practical means to describe the articulatory implementation of phonological contrasts within and across languages.
This view of the origin of transcription is represented on the left hand side of the diagram below. An underlying phonological representation which describes the sequence of contrasts needed to encode a particular linguistic message gives rise to articulation, which in turn gives rise to sound. Phoneticians observe the articulation and sound, and using a kind of alphabetic shorthand, write down a phonetic transcription.
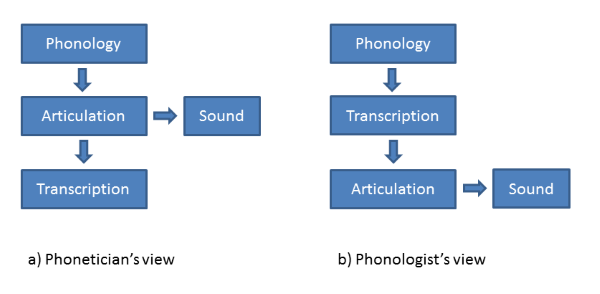
Somewhere in the history of Linguistics this story got lost. In the Sound Pattern of English, Chomsky and Halle use a "systematic phonetic" representation as the output of the morpho-phonological component in their transformational model of linguistics. In SPE, phonological representations which are phoneme-like (represented as bundles of features) are transformed by rules into a symbolic sequence identified as phonetic transcription. This transcription then forms the basis for articulation and sound generation. In other words, the underlying model of SPE is more like the right-hand side of the diagram above.
Why does this matter? It comes down to the objectivity of phonetic transcription. In model (a), transcription is the subjective product of a Phonetician - it's an approximation to the truth and different observers may come up with different accounts. Indeed we would predict this since observers, even trained Phoneticians, vary enormously in their listening skills and language backgrounds. Whereas in model (b), transcription is part of the mental processing required to speak, and for any given utterance there is but one transcription actually used by the speaker on any given occasion. This raises the status of phonetic transcription from "an opinion" to "fact": a transcription can now be right or wrong.
My opinion is that model (a) makes more sense: we start off by observing articulation and building a shorthand for writing it down. From this written form we observe certain patterns in articulation which lead us to believe there are a small number of discrete contrasts being used to encode pronunciation, but that the processes of articulation mess these up a bit, so we see a lot of contextual variability in the surface form of these underlying units. It makes sense that this contextual variability is strongly influenced by the limitations of articulation, constraints on sound generation and also constraints on our auditory perception.
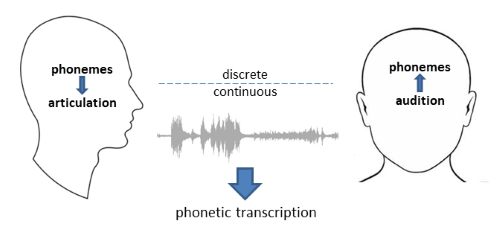
Model (a) also has the added bonus of making the difference between Phonetics and Phonology more explicit. Phonology is the part of speaking that is involved in discrete operations on symbols and sequences. Phonetics is that part to do with the the continuous movements of articulators and the form of sound. Transcription is a tool of the Phonetician, not part of Phonological processing. Maybe this diagram makes the idea clear:
- Suprasegmental units
Although the phoneme sequence is (by definition) sufficient to identify words, the speaker also has freedom in how the segments in the sequence are timed, how well they are articulated, and what character they have in voice quality, voice pitch or loudness. Since these aspects operate across multiple segments (over domains such as syllables, feet, intonation phrases, turns or topics), these aspects are called suprasegmental.
Suprasegmental units fall under three headings (see Laver 1994, Ch.4):
- Settings: these are preferences the speaker shows for particular articulatory state. For example, a speaker might choose a closed jaw position, or a partially-lowered velum, or choose a breathy voice quality. One way of thinking of a setting is as a kind of default or average position of the articulators to which a speaker returns after executing the articulator movements required for the segmental string.
- Stress patterns: these refer to the relative salience of regions of an utterance to listeners. Speakers can make some regions more salient by speaking them more loudly, more carefully, more slowly or with a change in pitch; alternatively speakers can make regions less salient by speaking them more softly, more casually, more quickly or with little change in pitch.
- Tone and intonation: these refer to changes in pitch which are associated with syllables, words or utterances. Languages with lexical tone use pitch movements to differentiate words, while intonational languages use pitch movements to signal utterance-level features such as sentence function and focus.
We return to the topic of suprasegmental effects in lecture 8.
- Linguistics and Paralinguistics
There is more to speech than a message encoded in phonological and grammatical units. The segmental and suprasegmental phonetic elements that are used to encode language in spoken form are called the linguistic aspects of Phonetics. But aspects such as 'tone of voice' or 'speaking style' are both phonetic and communicative, but not linguistic. We call these paralinguistic aspects of Phonetics. Paralinguistic phonetic phenomena are often implemented using suprasegmental elements such as speaking rate, articulatory quality, voice quality, average pitch height and so on and are used to communicate information about affect, attitude or emotional state. These features also play a role in the co-ordination of conversation among multiple communicating speakers.
We return to the topic of paralinguistic effects in lecture 9.
Readings
Essential
- The Principles of the International Phonetic Association, in Handbook of the International Phonetic Association, Cambridge University Press, 1999. [PDF on Moodle].
- Paul Tench (1978). On introducing parametric phonetics. Journal of the International Phonetic Association, 8, pp 34-46.
Background
- John Laver, Chapter 4 The phonetic analysis of speech, in Principles of Phonetics, Cambridge University Press, 1994 [available in library]. A more detailed account of the principles behind phonetic transcription than presented here. Recommended.
Laboratory Activities
The lab session involves two activities that explore the relationship between parametric and segmental accounts of speech production.
- Generating a parametric analysis from a segmental transcription
You will be provided with a slow-motion x-ray film of a speaker saying the utterance
She has put blood on her two clean yellow shoes
On the form provided, sketch the change in position of the following articulators through the utterance, aligned to the given segmental transcription: (i) jaw height, (ii) velum open/close, (iii) height of back of tongue, (iv) height of tip of tongue, (v) lip opening.
- Interpreting speech kinematic signals
You will be provided with signals related to speech articulators (captured using electromagnetic articulography (EMA)).
Using your knowledge of speech articulation and parametic analysis, you will identify which signals correspond to which English words.
Research Paper of the week
Articulatory Imaging
- E. Lawson, J. Scobbie, J. Stuart-Smith, "Bunched /r/ promotes vowel merger to schwar: An ultrasound tongue imaging study of Scottish sociophonetic variation", Journal of Phonetics 41 (2013) 98-210.
The availability of new methods for tracking and imaging articulation has created new challenges for theories of speech production. Tracking systems like the Carstens Electromagnetic Articulograph allow the positions and movements of articulators to be measured precisely in speaking. Imaging systems like Magnetic Resonance Imaging allow the soft tissues inside the head to be imaged non-invasively while the subject is lying in a scanner. But can theories predict how the articulators would move for a given utterance? Do the movements of articulators provide explanation for observed acoustic, phonetic or phonological effects?
This article describes how an ultrasound imaging system can provide an explanation of some observed sociophonetic variation in articulation. The ultrasound scanner - like that used in hospitals - is placed under the chin to image the upper surface of the tongue. Stills from the video are made at points where /r/ articulations are being realised and show how different speakers use different tongue shapes: either a raised tongue-front version or a bunched version. This difference is then used to explain why different coarticulatory effects are seen in different social groups. Interestingly, phoneticians have noted the different types of /r/ for some time, but it only imaging like this that provides empirical evidence.
Application of the week
Personal Speech Dictation
Speech dictation systems allow you to dictate documents directly into your word processor. Typically they are designed to operate in quiet office environments with a good quality microphone. Usually you need to be personally enrolled into the system by reading a short text; the system uses that to determine the particular characteristics of your voice. Dictation systems also scan the documents that you have on your computer; they use these to establish your typical vocabulary and your frequent word combinations. Dictation systems are particularly useful for people who work with their eyes or hands busy on other tasks (such as map-makers or dentists) or for people suffering from repetitive strain injury to their wrists.
Personal dictation systems are available for all major computing platforms in the most common world languages. The Microsoft speech recognition system is available free on modern versions of Windows. You can read a (somewhat technical) history of speech recognition systems at the reference below:
- X. Huang, J. Baker, R. Reddy, "A Historical Perspective of Speech Recognition", Communications of the ACM, 57 (2014) 98-103.
Reflections
You can improve your learning by reflecting on your understanding. Come to the tutorial prepared to discuss the items below.
- What is wrong with calling the human speaking apparatus the vocal tract?
- How could we tell whether some aspect of human anatomy or physiology is specialised for language?
- What are some advantages and disadvantages of parametric transcription compared to segmental transcription?
- Put into your own words the process by which the symbols on the IPA chart are chosen.
- When are diacritical marks on the IPA chart useful?
Word count: . Last modified: 19:25 10-Oct-2020.