6. Measuring Syllables
Learning Objectives
- to review the defining acoustic-phonetic character of consonant sounds as components of syllables
- to appreciate the problems associated with finding simple measures to describe consonant acoustics
- to learn about different measures for describing the average spectral envelope of fricatives and nasals
- to learn about methods for measuring formant transitions
- to learn about methods for the statistical modelling of spectral sequences
- to gain experience with instrumental methods for collecting the spectra of fricatives and for measuring voice onset time
- to gain practice with statistical techniques for dimension reduction and classification.
Topics
- Why measure syllables?
The measurement of the acoustic form of consonantal articulations is more difficult than that of vowels because: (i) the significant characteristics of consonantal articulations cannot be readily reduced to a single spectral slice since they have significant dynamic features; (ii) consonantal articulations that involve constrictions in the vocal tract will have an impact on the sources of sound energy in the tract as well as on their filtering; (iii) obstruent articulations impact the acoustic characteristics of neighbouring sounds, indeed many cues to consonant identity are found in adjacent vowels (and vice-versa); and (iv) there is less agreement on which acoustic measures are adequate to represent consonantal quality, and the underlying acoustic models of consonant production are less well understood.
Since consonantal sounds are rarely found in isolation from a syllabic nucleus. It could be argued that consonantal articulations are better thought of as parts of syllables rather than separate events. Thus a [b] is not a sound, but a way of starting a syllable such as [bɪt]. The advantage of this interpretation is that we don’t expect that [b] will have the same form before all vowels or in all syllable positions. The implications are that we will need our measurements of consonants to be context-sensitive. We should not expect to be able to make a satisfactory acoustic comparison of two consonants if they were collected in different contexts.
- Approximants
The semi-vowels [w] and [j] have articulations that are similar to vowel articulations. The formant frequencies for [w] are similar to those for [u], while the formant frequencies for [j] are similar to those for [i]. The liquids [l] and [r] have articulations distinct from vowels and hence have their own distinct formant pattern. The quality of [l] is strongly affected by the position of the back of the tongue, which leads to a range of formant frequencies and to sounds which vary in 'darkness' or velarisation. Formant frequencies for [r] are strongly affected by any retroflexion of the tongue, which can lead to a dramatic lowering of the third formant F3. In general, approximants differ from diphthongs by the speed of the gestures and the subsequent formant transitions that arise.
- Fricatives
All phonetic fricatives involve turbulence as a source of excitation in the vocal tract. Turbulence arises when fluid is forced to flow at a high speed through a constriction or when fast moving fluid mixes with stationary fluid. While at low speeds the fluid flow is smooth and predictable, at high speeds eddies and counter currents arise which create a disturbed flow of an unpredictable nature. This turbulent flow in air gives rise to random pressure variations that we hear as an aperiodic or noise waveform. Turbulence in the vocal tract arises from two main causes: (i) when air flow becomes turbulent as it passes through a constriction, e.g. at the glottis or at the lips; (ii) when a constriction creates a high-velocity jet of air which hits a stationary sharp-edged obstacle, e.g. in /s/, where the alveolar constriction directs a jet at the upper teeth.
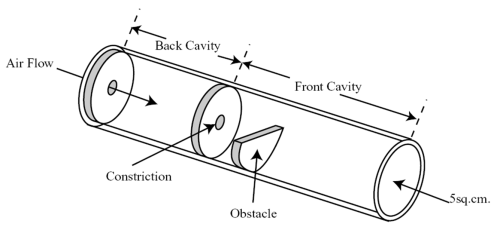
Shadle’s model is a general model of fricative production, whereby air flow becomes turbulent both in a constriction and at an obstacle. The spectral shaping of the turbulence is mostly performed by the front cavity, although there are minor effects caused by the back cavity. The presence of the obstacle in the front cavity also affects its resonant characteristics.Shadle's fricative model (1990) is able to recreate most aspects of fricative acoustics. Little is known in detail about the form of the spectrum of turbulent excitation in the vocal tract. We assume it is relatively flat in the speech frequencies from 1k to 10kHz. The noise excitation is generated close to the point of constriction and relatively little energy passes back through the constriction from the posterior cavity to the anterior cavity. This means that most of the spectral shaping of the excitation is caused by the response of the cavity anterior to the constriction. Coarticulatory changes in the size/shape of the front cavity will then have significant effect on fricative quality. See this example of vowel coarticulation on /h/:
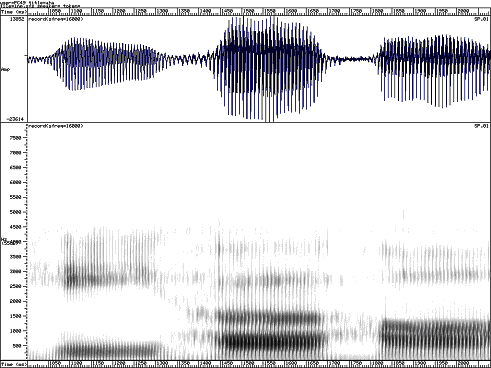
Spectrogram of /hiːhɜːhɑː/ showing coarticulation of /h/ with following vowel.In voiced fricatives like [z], vocal fold vibration occurs in the larynx while simultaneous turbulence is generated close to the constriction. Sound from the periodic source must pass through the constriction (or through the flesh of the neck) and is quiet and predominantly low-frequency. Sound from the aperiodic source is modulated by the changing air-flow pattern caused by the periodic interruptions in flow caused by the vibrating vocal folds. This pulsed turbulence can be clearly seen in wide-band spectrograms:
asa aza 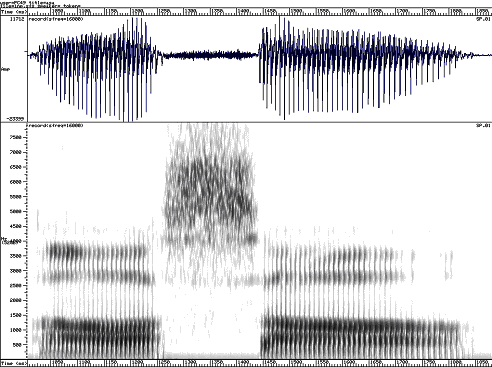
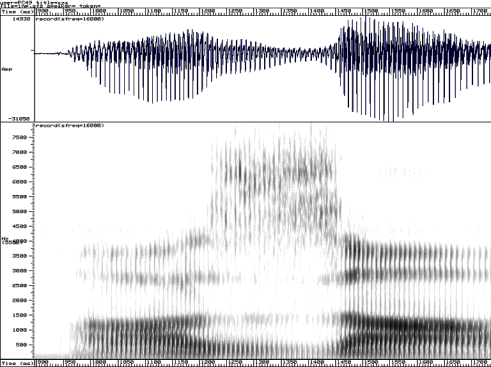
- Plosives
Place information for plosives comes from the spectral envelope of the plosive bursts and the effect of the plosive articulation on surrounding vowels.
The spectra of plosive bursts are similar to the spectra of fricatives made at the same place: this is because the anterior cavity is similar for both. The closing and opening gestures of plosives affect the formant pattern of the vowel going into and out of the obstruction. If we study the formant frequency movements that occur as an obstruction is made we see a lowering of F1 for all places of articulation, and changes in F2 and F3 which vary according to the place of articulation. These formant transitions are perceptually important clues (or cues) to the manner (F1) and the place (F2 & F3) of the consonant.
b p 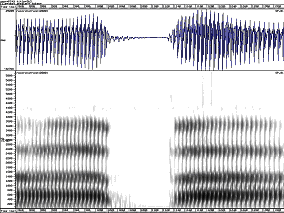
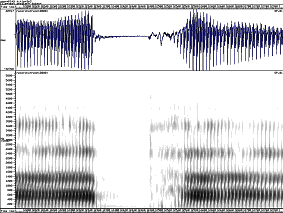
d t 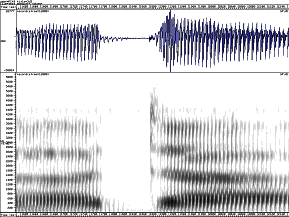
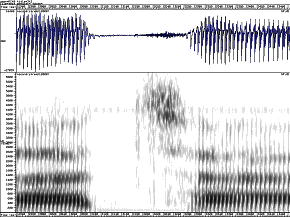
g k 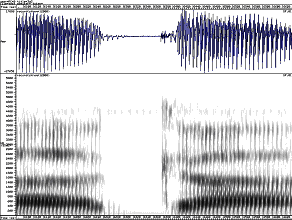
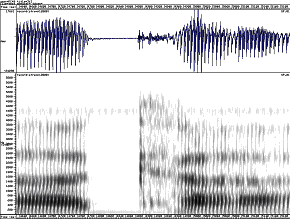
Spectrograms of plosives, showing cues to place and voice
It is important to understand that the exact shape of the formant transitions will vary according to the neighbouring vowel: they must start at the formant frequencies for the preceding vowel or they must end at the formant frequencies for the following vowel. However the frequency to which each transition is directed seems to be fairly consistent for a given consonant across different vowel contexts. These are called the consonant’s locus frequencies (Ohman, 1966).
Place Burst Centre Frequency F2 Locus Frequency F3 Locus Frequency Bilabial Lower than vowel F2 Low Low Alveolar Higher than vowel F2 Mid High Velar Close to vowel F2 High Mid The voicing cues for plosives include the voice onset time, the presence of aspiration, the presence of an audible F1 transition, the intensity of the burst and the duration of the preceding vowel. There are notable differences in cues to voicing across languages: some do not use aspiration, others have a three-way contrast.
English /p/ +ve VOT & aspirated 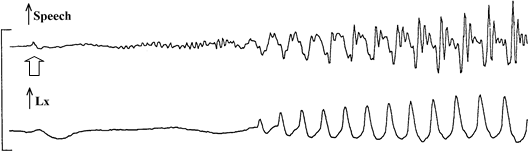
English /b/ zero VOT 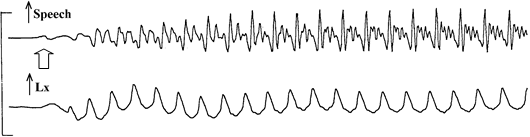
French /p/ zero VOT 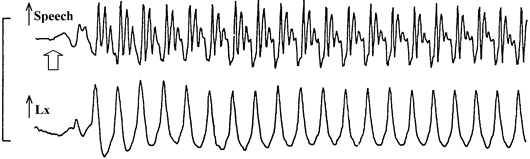
French /b/ -ve VOT 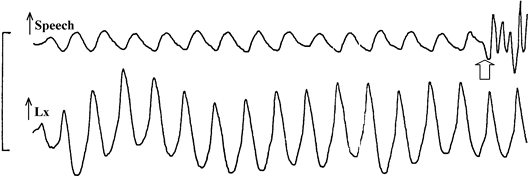
Voice Onset Time variation for plosive voicing
The spectrum of aspiration is much like the spectra of [h], and is variable depending on the following vowel articulation.
- Nasals
Nasal consonants involve a lowering of the soft-palate (velum) which links in the nasal cavities as additional acoustic resonators. The manner cues for nasals include the presence of a low-frequency resonance due to the nasal cavity, and the rapid fall and rise in energy as the nasal is made and released. The place cues to nasals mostly arise from the second and third formant transitions, as for plosives. In addition, the spectral shape of the nasal itself varies slightly with the place of the obstruction in the vocal tract. This seems to be due to the size of the cavity trapped behind the obstruction which modifies the filter characteristic of the branched tube.
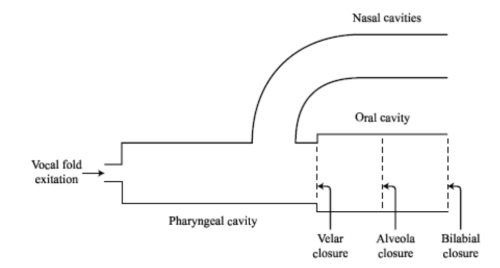
The nasalisation of vowels is cued by the presence of a low-frequency resonance and an increase in formant damping.
- Simple measures of consonants
The durations of consonants and consonant elements are relatively easy to measure, although suitable criteria need to be established for where timing measurements are to be made. For consonantal articulations involving different stages, the relative durations of components can provide useful information about variations in articulation. For example, plosives can be divided into vowel offset transition, stop-gap, burst, aspiration and vowel onset components. Voice onset time has been commonly used to study variation within and across languages (see, e.g. Lisker & Abramson, 1967). The average intensity of a consonant compared to adjacent vowels can be a useful measure to contrast consonant manner.
- Spectral measures of consonants
For continuant sounds, the average spectral envelope is a simple way to characterise the overall quality of the sound. This can be acquired using a filterbank.
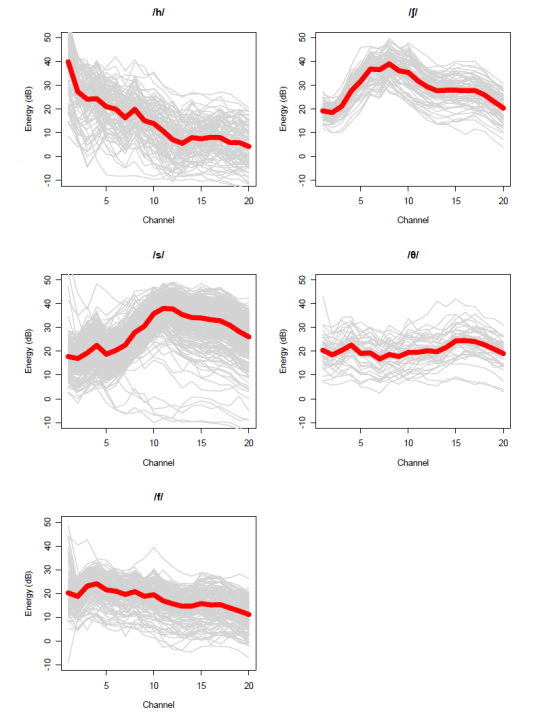
Time-averaged fricative spectra from 200 sentences of a male British English speaker, and mean spectrum. Frequency axis is 0-10kHz
To describe the envelope in fewer parameters, one might look at the spectral centre of gravity or other spectral moments (variance, skewness & kurtosis, see Forrest, 1988). Spectral envelopes can also be represented in fewer parameters through statistical analysis.

Linear Discriminant Analysis (LDA) performed on the time-averaged fricative spectra in the previous diagram. The labels represent the 5 fricative places of articulation and the axes are the first two discriminants.
- Formant transitions
The effect of an obstruent articulation on adjoining vowels can be characterised by studying the movement of the vowel formant frequencies as the obstruction is made and removed (see Van Son & Pols, 1999). In the formant locus frequency model, the dynamic characteristics of the F2 and F3 formant frequency transitions are indicative of the place of consonantal obstruction. The F1 transition is usually to a lower frequency for obstruction at any place. To obtain good tracks of formant transitions it can be beneficial to use a finer temporal resolution than normal (for example, Van Son & Pols used 25ms windows advancing just 1ms at a time).
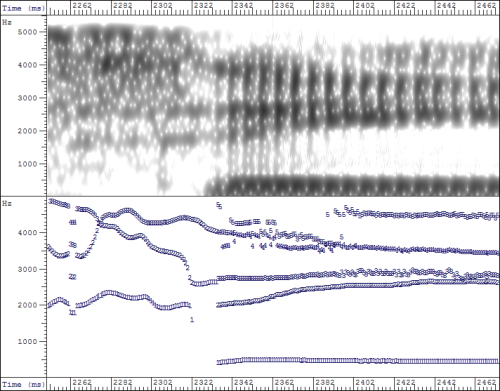
- Statistical Modelling
Piecewise-stationary segmentation
When studying consonantal realisations it may be unsatisfactory to compute an average spectrum across the duration of the consonant. For example, it makes little sense to calculate the average spectrum of a plosive across all phases: closing, closed, burst, and opening. Instead one might consider dividing the spectrographic form into sections each of which may be described by one average spectrum. Thus our plosive consonant might be described with four spectral sections.
Given a stretch of signal and the desired number of sections, methods exist for finding the temporal segmentation which minimises the overall spectral variability. For example:

The utterance "three mice" is divided into nine piece-wise stationary sections: (a) spectrogram, (b) 19-channel filterbank, (c) segmentation, (d) calculated average spectrum per segment..
Each temporal section is thus described by a single average spectrum. It is then possible to compute spectral means & variances of each section across multiple repetitions.
Hidden-Markov Models
Hidden Markov models (HMMs) are extensions of the segmentation idea described in the last section. Given a stretch of signal and a number of segments, an HMM will parse the signal into segments, associating each segment with a "state" in the model within which are stored the spectral mean and variance associated with each section.
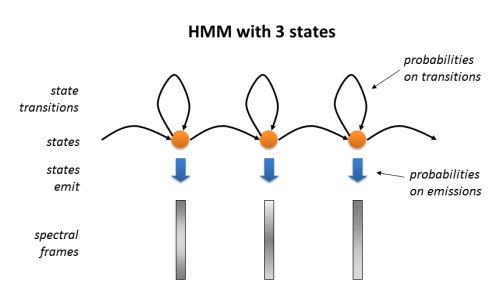
The power of the HMM comes from the fact that the models may be trained from data - for example from a whole corpus of utterances - and so discover both the best segmentation and the best spectral description of the signals as a sequence of spectral states. In a typical application, HMMs are constructed for each phonetic type (phonemes say) and initialised to a blank state. Then through cycles of alignment and updating with multiple utterances, the HMMs learn how to segment the phonetic element and how to represent each section as a set of spectral means and variances. A common strategy is to assign 3 states per phone model, and to build an overall model for an utterance using a concatenation of phone models given the supposed transcription.
A trained set of HMMs can be used to describe the distribution of typical spectral values for segments, or can be used to automatically align a given transcription against a signal. HMMs can be used to recognise an utterance (finding the HMM sequence that best explains the data), or used to choose between different pronunciations of an utterance (find which of two or more HMM sequences best explains the data).
References
- Ohman, S., "Coarticulation in VCV utterances: spectrographic measurements", J. Acoust. Soc. Am. 39 (1966) 151-168
- Forrest, K. et al, "Statistical analysis of word-initial obstruents: Preliminary data", J. Acoust. Soc. Am. 84 (1988) 115-123
- Shadle, C., "Articulatory-acoustic relationships in fricative consonants", in Hardcastle & Marchals (eds) Speech Production and Modelling, Kluwer, 1990.
Readings
- Lisker & Abramson, "The voicing dimension: some experiments in comparative phonetics", Proc. Sixth International Congress of Phonetic Science, Prague, 1967.
- van Son, R., Pols, L., “An acoustic description of consonant reduction”, Speech Communication 28 (1999) 125-140.
Laboratory Exercises
- Voice Onset Time
- Use the laboratory computers to acquire speech and Lx recordings of your production of
- Measure the Voice Onset Time in each case from the burst to the start of the first full phonation cycle.
- Enter your measurements into the data entry form (see Moodle) to generate a table of class responses. Variable 'VOT' contains the voice onset time measurements in milliseconds.
- Load the class results table into SPSS.
- Use SPSS to test the following null hypotheses at a significance level of 0.05:
- Choose an appropriate test and write down your interpretation of the test and the result.
- Fricative Quality
- A spreadsheet of fricative data may be found in y:/EP/fricspeaker.csv. This comprises analyses of 50 speakers saying /ɑːfɑː/, /ɑːθɑː/, /ɑːsɑː/, /ɑːʃɑː/ and /ɑːhɑː/. The fricative sections have been located automatically and the normalised average cross-sectional spectrum has been computed for each fricative using a 32-channel filterbank (500Hz bandwidth filters from 0-16000Hz). These may be found in columns C01-C32 in the spreadsheet. In addition the centre of gravity of the spectrum has been coded in column COG, and a measure of the variation around the centre of gravity has been coded in column WIDTH.
- Load the fricative data into SPSS and use Transform | Automatic Recode to recode the FRIC variable so it can be used in subsequent analyses.
- Using Graphs | Legacy Dialogs | Error bar | Summaries of separate variables, plot graphs to summarise the average filterbank spectrum for each fricative class. What features of the spectra are useful to discriminate fricative classes?
- Explore how the COG and WIDTH parameters may be used to discriminate between the fricative classes. Using Graphs | Legacy Dialogs | Scatter/dot, plot a scatterplot of fricatives against axes of COG and WIDTH. How well do these parameters work to discriminate fricative classes?
- Compute the first three principal components of the filterbank data, using Analyze | Dimension Reduction | Factor. Add the 32 filterbank energies to the list of variables. Under Extraction, request a fixed number of factors set to 3 factors. Under Scores, check to save the computed coefficients as new variables. Next plot scatterplots of fricatives against these new dimensions. How well do these parameters work to discriminate fricative classes?
- Use Linear Discriminant Analysis to classify the fricatives from filterbank data. Use Analyze | Classify | Discriminant. Add the 32 channels to the list of independents, and the fricative name as the grouping variable, with range set to 1-5. Under Classify, choose "Leave one out classification" and "Plot combined groups". You will get a performance score for the cross-validation recognition under "Classification Results". How well does classification work and where are the most errors?
- Repeat the discriminant classification using COG and WIDTH instead of the filterbank data. Then repeat using the 3 principal components. How does their performance compare to the filterbank data? What is your interpretation of the result?
/ ɑːbɑː , ɑːpɑː , ɑːdɑː , ɑːtɑː , ɑːɡɑː , ɑːkɑː /
The variance of VOT is the same for voiced and voiceless plosives"
"Mean VOT does not vary between voiced and voiceless plosives"
"Mean VOT of voiced plosives does not vary according to place"
Reflections
- Think of some non-speech situations when turbulence generates an audible noise.
- Why are the sibilant fricatives so much louder than the others?
- How and why does lip-rounding affect fricative quality?
- Why does the burst centre frequency for /k/ vary with vowel context?
- What differences in the form of /t/ can be observed in "grey tie" versus "great eye"?
Word count: . Last modified: 14:34 21-Feb-2017.