7. Variation With Context
Learning Objectives
- to make some sense of the concept of coarticulation in Experimental Phonetics
- to appreciate the differences between phonological, phonetic and dynamic influences on coarticulation
- to understand how Keating’s window model predicts the occurrence and variability of coarticulation
- to understand how Fowler’s coproduction model predicts the occurrence and variability of coarticulation
- to gain experience with instrumental methods for modelling formant transitions
- to gain practice with statistical tests for modelling the influence of discrete factors
Topics
- Why study contextual effects?
Observations about how articulation and sound production change in different contexts can provide insights into the planning of speech production. When the same phonological units are realised in different contexts (e.g. the same phoneme in different syllables), are the articulatory changes observed due to modifications in the phonological specification, in the design of the motor plan, or in the execution of the motor plan? Are changes in speech due to speaking style caused by variation in speaking rate, or are they also caused by changes in communicative load? Are phonological categories abstract entities distinct from the articulations needed to realise them? How do listeners compensate for contextual changes to recover perceptual constancy?
- Phonology & Phonetics
Phonological descriptions of speech are typically discrete in time and symbolic in value: for example phonemic transcription is a sequence of durationless context-independent symbols drawn from some small inventory. On the other hand, articulatory or acoustic descriptions of speech are continuous both in time and in value: an articulatory/acoustic description is a multi-dimensional graph of articulator position/acoustic form against time. We assume that the phonological units are the same in all contexts (context-free), while the articulator trajectories are different according to context (context-dependent). In this view, contextual effects arise in the mapping between phonological and phonetic levels. Thus the position of an articulator at time t (or the spectral characteristics of the sound at time t) is influenced by more than one phonological unit. This is the definition of coarticulation.
As an aside, it may be worth questioning this conventional picture. What if the units that are combined to generate the motor plan are not individual phonemes? Perhaps the motor plan for common consonant clusters or common syllables are pre-stored such that coarticulation is an integral part of their stored form rather than arising as part of on-line planning.
- Contextual effects at different levels
Contextual changes may occur at the phonological level, with segment choices changing with context (allophonic variation, for example). Contextual changes may arise in the planning of articulation, to ensure that the articulators are best placed given the time available (anticipatory coarticulation, for example). Contextual changes may also arise in the execution of articulation because of the inertia of the articulators themselves (carry-over coarticulation, for example). Isolating the causes of contextual effects to one level can be difficult, because it is possible (likely) that articulator planning is designed to accommodate articulator inertia, and because recurring articulator movement patterns can become phonologized, i.e. incorporated into the phonological specifications for the units.
- Types of contextual effects
In the literature you will find a range of names for different types of contextual effects. Let us take them in turn, with examples.
- Coarticulation: Coarticulation means 'joint articulation', that is a situation where one articulator is trying to satisfy more than one segment. A classic example is in the articulation of "car" and "key"; in the first, anticipation of the vowel moves the body of the tongue low and back and so the velar closure occurs further back in the mouth [k̠ɑ]; while in the second, anticipation of the vowel moves the body of the tongue high and front and so the velar closure occurs further forward in the mouth [k̟i]. The contextual variation of the two [k] sounds is caused by the joint articulation of the plosive and the vowel.
- Assimilation: Sometimes the gestural score is so modified by efficient planning that the resulting score is confused even in terms of what phonological segment sequence it represents. In "good boy" or "good girl", for example, it appears that the alveolar plosive can be substituted for a bilabial or velar plosive respectively: [gʊbbɔɪ], [ɡʊɡɡɜːl]. However, an alternative explanation is shown in the gestural scores below:
- Without assimilation:
tongue body ʊ vowel ɔ vowel ɪ vowel tongue tip alveolar closure lips lip closure - Anticipate lip closure:
tongue body ʊ vowel ɔ vowel ɪ vowel tongue tip alveolar closure lips lip closure - Drop alveolar closure:
tongue body ʊ vowel ɔ vowel ɪ vowel tongue tip lips lip closure - Elision: In the assimilation example above, we see how elements of the score which become redundant because of efficient planning (like the [d] in "good boy") can seem to be dropped. There are other situations in which elements can be dropped, perhaps simply because there is not enough time to articulate them, or because meaning is preserved without them. This dropping of whole phonological segments is called elision.
The coarticulation of [k] with the following vowel works work right-to-left and is a form of anticipatory coarticulation. Left-to-right coarticulation can also occur, although it is less common. This is called carry-over or perseverative coarticulation. An example of perseverative coarticulation is the carrying over of voicelessness from the plosive to the lateral in "please" [pl̥iːz].
In this explanation, there is no "shift" from /d/ to /b/, just a plan in which /b/ takes over the role of /d/ and the /d/ is lost. It is hard to call this 'coarticulation', since there is no real problem in producing an alveolar plosive in this context, and in any case the articulators for [b], [d] are different - so it cannot be the case that the change in articulation is due to the tongue tip being jointly articulated for both [d] and [b].
This combination of coarticulation and phonological re-writing is called assimilation.
Another common form of assimilation is devoicing, particularly of voiced plosives and voiced fricatives before voiceless sounds. Since all English voiced plosives and fricatives have voiceless counterparts, a loss of voicing can always be interpreted as a change in the identity of the segment itself (i.e. assimilation could arise from voicing coarticulation). It is common to hear "have to" spoken as [hæftʊ] for example.
It is interesting to note that there is nothing to stop voiceless segments being assimilated to voiced ones in the complementary context, e.g. "nice boy" as [naɪzbɔɪ]. However this kind of voicing assimilation doesn't seem to occur in English, although it does occur in Frenchː "avec vous" as [aveɡvu].
These examples of assimilation are right-to-left or anticipatory, but assimilation can occur left-to-right, as in "happen" [hæpm̩] or in "don't you" [dəʊntʃuː].
Assimilation is important diachronically, since if a motor plan is ambiguous about which phonological sequence it represents then new generations of listeners can misinterpret the phonological form of the word. Historically this may have arisen in the voicing agreement of the plural morpheme "-s" to the voicing of the last consonant in the word; or the pronunciation of "in+possible" as /ɪmpɒsɪbl̩/. A newspaper was once just paper /peɪpə/ containing news /njuːz/, but now for many people it is a /njuːspeɪpə/.
Consider the phrase "next week", it is indeed possible to articulate this as [nekstwiːk] but it is also very often heard as just [nekswiːk]. The [t] is tricky to articulate between consonants, and it is unlikely that the listener will interpret the result as "necks week".
In a famous experiment, Browman & Goldstein used articulator tracking to study tongue tip movement in the phrase "perfect memory", which contains a tricky articulatory sequence [ktm]. When spoken quickly, the bilabial closure precedes the velar release and the [t] is elided to get [pɜːfek̚ memriː]. The scores below show the process:
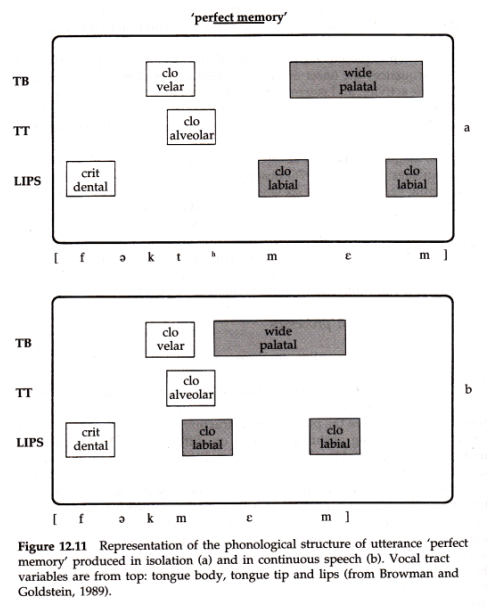
But articulator tracking gave an interesting result around the elided /t/ segment - the tonɡue tip still made some brief movement, even though there were no acoustic consequences because of the lip closure.
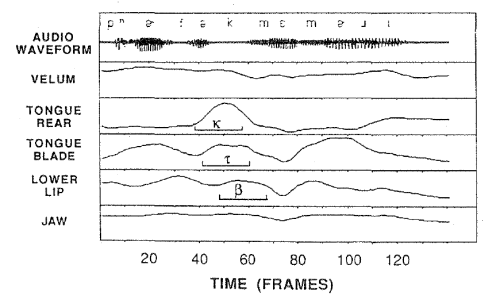
The fact that elements of the motor plan are still executed even when they are redundant is evidence that planning is an active process performed "on the fly" while speaking.
One important aspect of elision that is worth noting, is that elision does not disturb the speech rhythm. That is, deleting segments does not speed up the speaking rate (the order is the other way around: increasing rate causes elements to be dropped). The consequence of this is that listeners can sometimes tell from the timing of the utterance that elements have been elided. Consider the phrase "book-case" as [bʊkkeɪs]; after elision of the first [k] segment, we get [bʊkːeɪs] and not [bʊkeɪs]. This is an example of gemination.
- Theoretical models of coarticulation
Target models of coarticulation
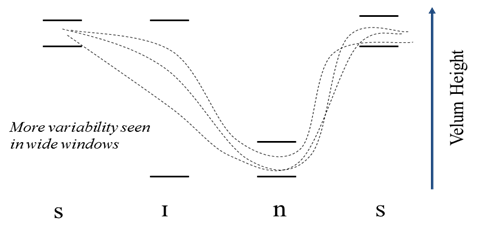
In the so-called target based models of speech production, each context-independent phonological unit specifies a set of articulatory or acoustic targets which constrain the articulation or the sound produced. For example, in Keating’s Window model (Keating 1990), each phonological unit delimits the maximum and minimum allowed position for each articulator in the middle of the unit. The articulator is free to take any path through the segment providing that it passes through the window. In the window model, most coarticulation and most variation in coarticulation is predicted where the windows are wide, that is when the phonological segment underspecifies the articulator position.
Coproduction models of coarticulation
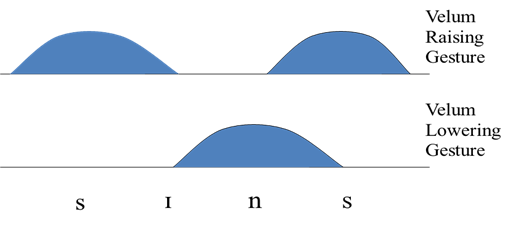
In the so-called co-production models of speech production (Fowler and Saltzmann 1993), each phonological unit specifies a context-independent articulatory gesture. These gestures may take longer to execute than the duration of the segment, and so naturally overlap in time. It is the overlapping of gestures that leads to context-dependent realisation. Such a model leads naturally to an explanation of why greater coarticulation occurs at faster speaking rates, when more overlap between gestures is present.
- Experimental methods for studying coarticulation
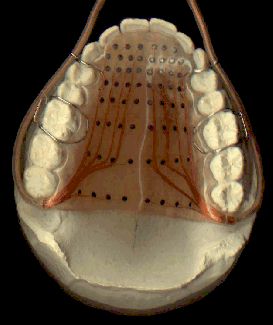
Contemporary research in coarticulation has been aided by the development of instruments for tracking articulator movement. Air-flow masks which measure oral and nasal airflow have been used to study nasal coarticulation. Electropalatography uses a dental plate that sits over the alveolar ridge/hard palate and which detects tongue contact using an array of electrodes. Electromagnetic articulography (EMA) uses a 3D sensing cage around the head to detect the location and orientation of small electrical coils glued to the articulators. Ultrasound can be used to image the shape of the top surface of the tongue from a transducer placed beneath the chin. Magnetic Resonance Imaging (MRI) is improving in resolution and speed, such that it is becoming possible to image articulator movement in real time. Acoustical measurements provide an indirect means of assessing changes in articulator position.
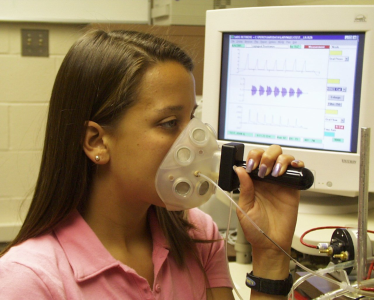
Oral/nasal mask Electro-palate 

Electromagnetic Articulography Ultrasound tongue imaging 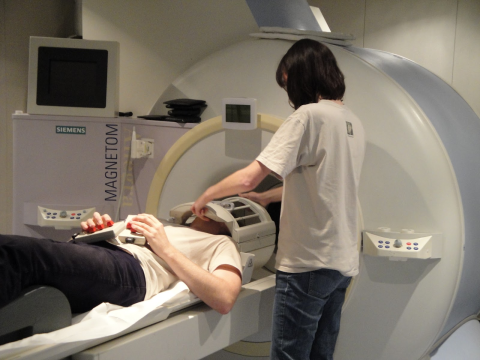
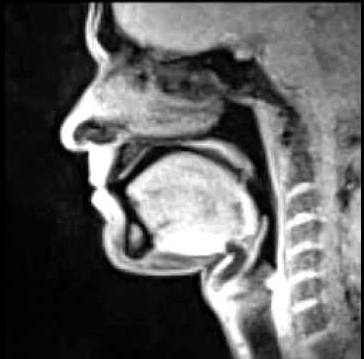
Magnetic Resonance Imaging Electropalatography Example

EPG traces for k-l overlap in "weakling"
Electropalatography and Airflow Example
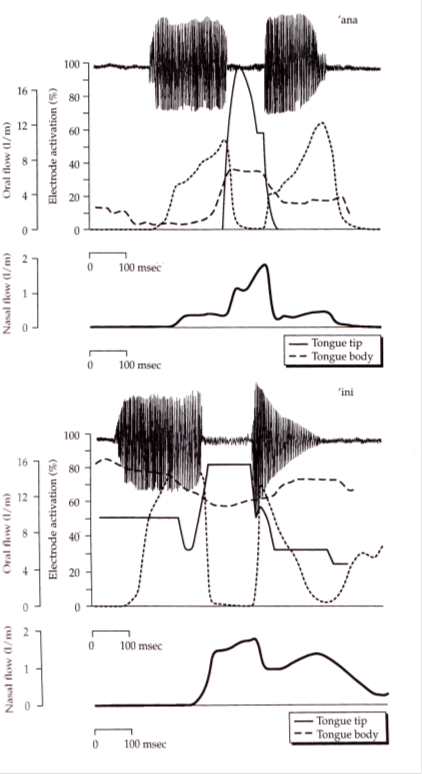
Acoustic signal, oral and nasal flow curves and synchronised EPG curves for /ana/ and /ini/, from Farnetani 1986.
Electromagnetic Articulography Example
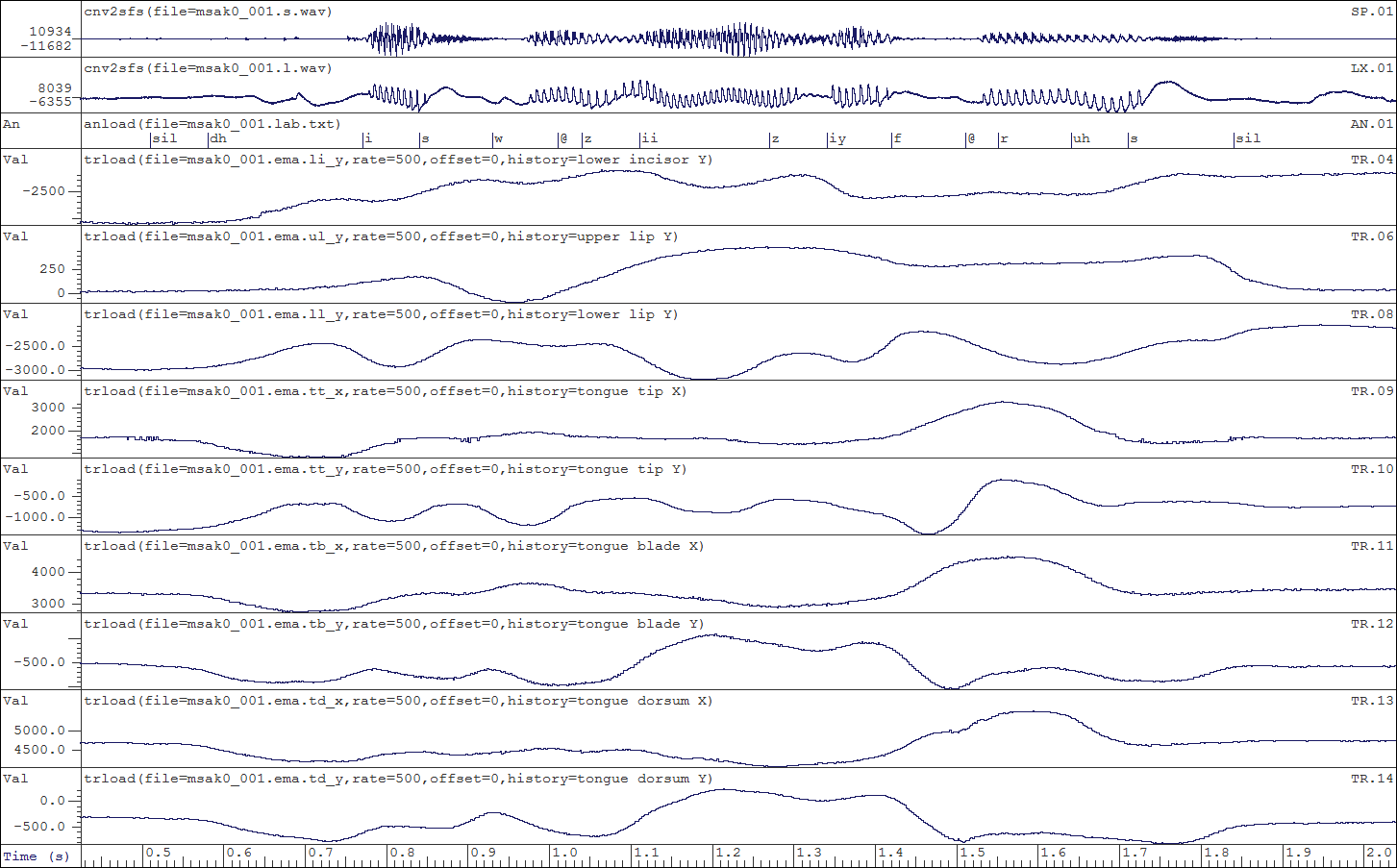
Example EMA data for sentence "This was easy for us" from the MOCHA corpus.
Articulatory data sets
- Seeing Speech: ultrasound and MRI videos of example articulations.
- MOCHA-TIMIT corpus: Corpus of audio recordings with EMA, EPG and Laryngograph signals.
- MRI-TIMIT: Multimodal Real-Time MRI Articulatory Corpus.
- Quantitative models of coarticulation
Quantitative models of coarticulation are still in their infancy. Ideally one would want a model that would predict articulator position from a phonological transcription which could be evaluated in how well the contextual effects that arose were similar to those found in human speakers. Blackburn and Young (2000) attempted to fit a probabilistic version of Keating’s Window model to articulatory data collected by an x-ray microbeam system.
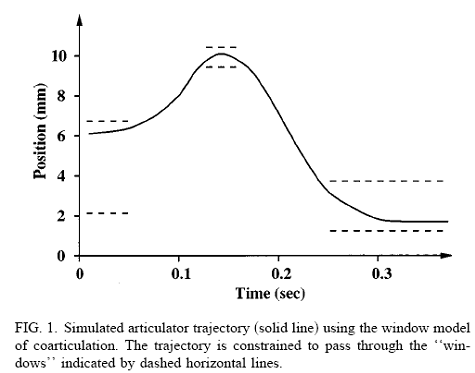
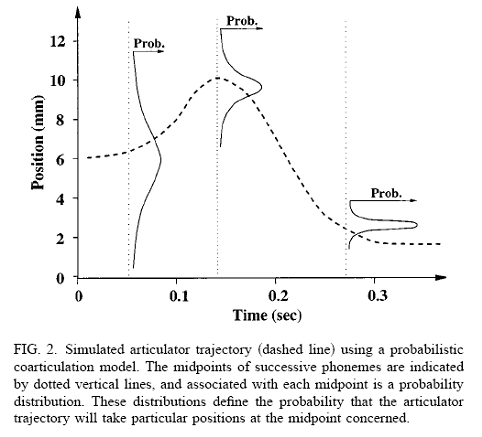
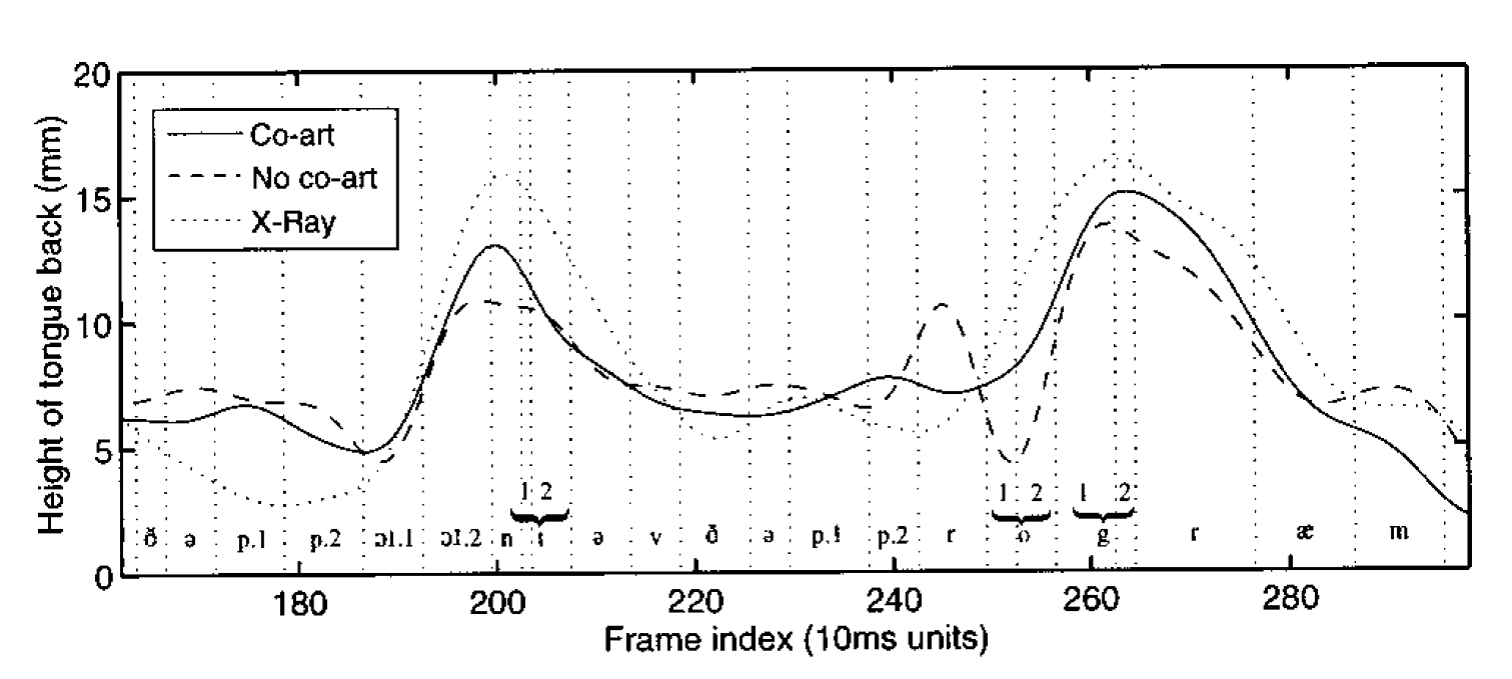

Models of coarticulation could also be evaluated using an articulatory speech synthesizer, a computational simulation of the vocal tract controlled by articulator position. Example articulatory synthesizers are: Vocal Tract Lab by Peter Birkholz is a 3D simulation of a vocal tract with impressive sounding speech that has been used for studies of coarticulation; VTDEMO is a simpler 2D vocal tract simulation designed for teaching.
- Curve fitting
To study coarticulation it is often necessary to extract measures from parameter tracks that change over time: for example to track formant frequency changes. The general principle is to fit a line or curve to a series of measurements over time, so as to describe the change in terms of the parameters of the fitted curve. Here are some example fitted curves:
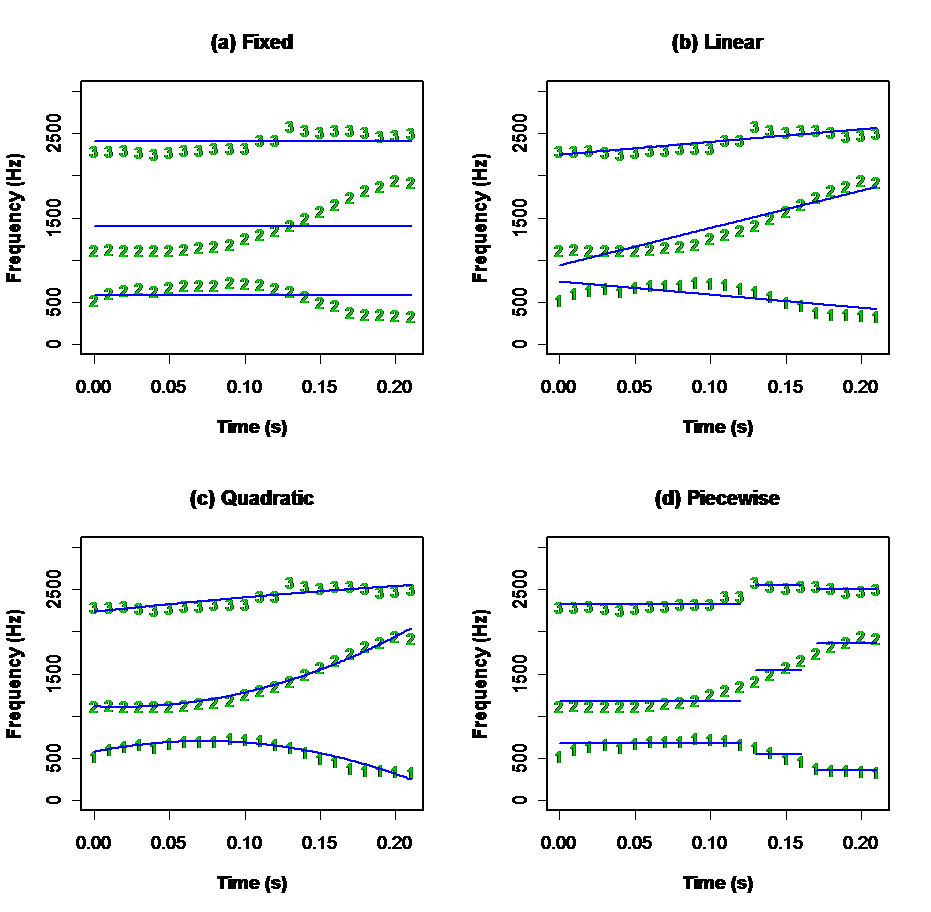
Modelling parameter dynamics over a segment with (a) a mean calculated over the whole segment (3 numbers), (b) a straight line fit (6 numbers), (c) a quadratic line fit (9 numbers), (d) a piecewise-stationary fit (9 numbers). Data is first three formant frequencies for /aɪ/ diphthong.
Least squares fit of a quadratic curve
If the equation of the best-fitting quadratic is:
y = a + bx + cx2
Then the best values for a, b and c can be found from the solution of this set of equations (expressed here in matrix notation for convenience):
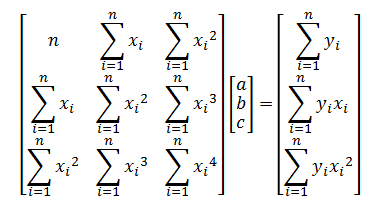
References
- P.A.Keating, "The window model of coarticulation: articulatory evidence", In Beckman & Kingston (ed) Papers in Laboratory Phonology 1, Cambridge University Press (1990), pp451-470. [on Moodle]
- C.Fowler and E. Saltzman, "Coordination and coarticulation in speech production", Language and Speech 36 (1993), pp171-195. [on Moodle]
Readings
- E. Farnetani & D. Recasens, “Coarticulation and connected speech processes”, in Handbook of Phonetic Sciences (ed W.Hardcastle, J. Laver & F. Gibbon), Wiley-Blackwell 2010. [on Moodle]
- C.S. Blackburn & S. Young, "A self-learning predictive model of articulator movements during speech production", J.Acoustic Soc. Am. 107(3), 2000, pp1659-1670. [on Moodle]
Laboratory Exercise
- Coarticulation of Formant Frequencies
- Use the ESection program to record these nonsense words (at 11025 samples/sec) and measure the F1 & F2 frequencies at the centre of the /ə/ vowel in each case:
- Can you see any pattern in these measurements? For example do the formant frequencies of the /ə/ seem to vary with vowel context or consonant context?
- In the file y:\EP\mark-cvc.csv, you will find measurements of F1 & F2 for 10 repetitions of these utterances from a single speaker. The factors are “initial” {3,A}; “consonant” {B,G}; and “final” {3,A}.
- Using SPSS, calculate some box-plots to explore the F2 values across the different conditions to try and find a systematic pattern in the data. Check that the general patterns found in the data match your own.
- What evidence can you find of coarticulation? Can you find evidence that /g/ interferes with the coarticulation of /ə/ with /ɑː/?
- Using Analyze | General Linear Model | Univariate, explore which factors and which combinations of factors significantly influence the value of F2 in these data. Use "f2" as the dependent variable and "initial", "consonant" and "final" as fixed factors. Under Options, check "Parameter Estimates". Interpret the significant effects found by the model. Which vowel effect is stronger: anticipatory coarticulation or carry-over coarticulation? (If you are interested you can also perform a Multivariate GLM analysis using both f1 and f2).
Phrase F1 (Hz) F2 (Hz) 'ɜːbəbɜː 'ɜːbəbɑː 'ɑːbəbɜː 'ɑːbəbɑː 'ɜːɡəɡɜː 'ɜːɡəɡɑː 'ɑːɡəɡɜː 'ɑːɡəɡɑː - Coarticulation of articulator position in EMA data
- The file y:\EP\fsew.csv contains measurements of articulator positions of one speaker collected using EMA from the MOCHA-TIMIT corpus. Each row describes the x (horizontal) and y (vertical) positions of the articulators: Lower-incisor (LI), upper-lip (UL), lower-lip (LL), tongue tip (TT), tongue blade (TB), tongue dorsum (TD), and velum (V) sampled at the centre of each phonetic segment. The columns SEG contains the name of the segment, PSEG the name of the preceding segment, and NSEG the name of the next segment. The columns TYPE contain the class of the current segment, PTYPE the class of the previous segment, and NTYPE the class of the next segment. The column PVOWEL contains the identity of the previous vowel nucleus, and NVOWEL contains the identity of the next vowel nucleus.
- Load the data file into SPSS and use it to explore the effects of anticipatory coarticulation. You will need to use Transform | Automatic Recode to recode all the string variables into factors (e.g. TYPE=>TYPEx, NTYPE=>NTYPEx, etc).
- Explore these questions:
- Does velum height (VY) for a vowel (TYPE=VOW) change depending on whether the next segment type (NTYPE) is a nasal? Select all rows for TYPE=VOW. Calculate a boxplot of VY against NTYPE. Interpret the graph. Fit a Univariate General Linear Model using VY as the dependent variable and NTYPE as a fixed factor. Under Options, choose "Parameter Estimates". Interpret the estimated model.
- Does lip protrusion (LLX and ULX) for /s/ (SEG="s") vary with the identity of the following vowel (NSEG when NTYPE=VOW)? Select all rows for which SEG="s" & NTYPE="VOW". Calculate a boxplot of LLX and ULX against NSEG. Interpret the graphs. Fit a Univariate General Linear Model using LLX (or ULX) as the dependent variable and NSEG as a fixed factor. Under Options, choose "Parameter Estimates". Interpret the estimated model.
- If you have time, see if you can use SPSS to investigate other questions, for example, do the upper and lower lips tend to move together? How does the velum move? Which vowels vary most in tongue height?
Reflections
- For each of these, discuss whether they should be most appropriately described in terms of phonological changes, motor plan changes or articulator dynamical effects:
- Rounding of /s/ before rounded vowel
- Clear vs. dark /l/
- Undershoot of vowel formant frequency in /ɡɒɡ/ vs /bɒb/
- Linking /r/ in "butcher and baker"
- Assimilation in “this shop”
- Find other examples of contextual changes that clearly operate at a phonological level.
- Find other examples of contextual changes that clearly operate at a motor plan level.
- Find other examples of contextual changes that clearly operate at an articulator dynamics level.
Word count: . Last modified: 11:53 01-Mar-2018.