
UCL Enhance Help File
| Program: | Vs 1.0 |
| Help file: | Vs 1.0 |
Contents: Internet links:
¤Controls
¤Recording
¤Displays
¤Statistics
¤Enhancement
¤Learn more
¤Bug reports
¤Copyright
¤UCLEnhance
Home Page
¤Enhance Project
Home Page
¤SFS
Home Page
¤Speech &
Hearing
Institute
UCLEnhance is a program for the enhancement of the intelligibility of speech recordings. The program incorporates a number of standard techniques for manipulating the overall amplitude of the signal and for the removal of steady-state additive noise. However, the program is unusual in its ability to detect and enhance selective regions of the speech signal based on their phonetic properties. This phonetically-sensitive method of enhancement was developed and evaluated in the Department of Phonetics and Linguistics at University College London under two research project grants funded by the UK Engineering and Physical Sciences Research Council.
For information about the scientific basis for the phonetic enhancement method, please refer to the publications listed in the Learn more section.
UCLEnhance is a simple application that is complete in itself but which is also designed to be compatible with the Speech Filing System (SFS) tools for speech research.
Controls
Toolbar
- New file. Use to clear the current display to prepare for a new recording.
- Open file. Use to open an existing signal file stored on disk. Supports standard Microsoft RIFF format (.WAV files) as well as SFS file format.
- Save Original Signal. Use to save a new recording to a disk file, or to save an existing signal file under a new name. Both WAV and SFS file formats are supported. Saving to an existing SFS file does not overwrite other data in the file.
- Save Enhanced Signal. Use to save the enhanced signal to a file. Both WAV and SFS file formats are supported. Saving to an existing SFS file does not overwrite other data in the file.
- Print. Use to reproduce the current display on the printer. Note that printouts are produced in landscape format by default. Cursors are not printed.
- Record. Use to record a new speech signal. Selection of the input device and input sensitivity must be made through the use of the system volume controls, see recording below.
- Play Original. Use to replay the region of the original signal displayed or between cursors. Selection of the output audio device and volume must be made through the use of the system volume controls.
- Play Enhanced. Use to replay the region of the enhanced signal displayed or between cursors. Selection of the output audio device and volume must be made through the use of the system volume controls.
- Enhance. Brings up the dialogue where the enhancement settings can be made.
- Waveform. Use to display an amplitude waveform graph of the speech signal. See Displays.
- Wideband Spectrogram. Use to display a wide bandwidth spectrogram of the speech signal. This is calculated dynamically from the speech signal as required. See Displays.
- Annotations. Use to label the phonetic events discovered by the phonetic enhancement method.
- Scroll left (Left arrow). Use to move the display to an earlier part of the signal.
- Zoom in (Down arrow). Use to focus the display on a smaller section of the displayed signal. To zoom in, first set the area of interest with left and right cursors.
- Zoom out (Up arrow). Use to undo one level of zoom.
- Scroll right (Right arrow). Use to move the display to a later part of the signal.
Other menu options
- Signal Statistics. This option displays some statistics about the original and enhanced signals, such as their range and power. See the Statistics section for details.
- Replace Original. This option replaces the currently original signal with the current enhanced signal. Take care, there is no way of going back! You are advised to save the original signal before using this option.
Cursors
With a waveform loaded and displayed, you can set left and right cursors using the left and right mouse buttons. The left cursor is blue, the right cursor is green. These cursors indicate the start and stop time for various operations:
- for replay the signal replayed is the region between the cursors.
- for zoom in the region between the cursors is expanded to fill the display.
- for scroll left the right cursor becomes the new right edge of the display.
- for scroll right the left cursor becomes the new left edge of the display.
Recording
Most PCs have two input lines, one designed for a microphone input and one designed for a 'line' level input (from e.g. a tape recorder). Some PCs are also able to record output from audio CDs played in the computer. Once your signal source is connected to the computer, you need to select it using the Volume Control application. This can be found under the Start/Programs/Accessories/Multimedia menu on Windows 95/98/NT systems.
To record from a microphone:
- ensure that it is connected to the microphone input to the PC.
- ensure that the microphone input device is selected in volume control.
- ensure that the input volume and overall record volume are at moderate levels.
- request the record menu option in UCLEnhance and select 'Test Levels' to check that signals are getting to the program.
- adjust the volume controls so that at no time does the peak level reach the right hand side of the display when recording.
- select 'Record' to record the signal, 'Stop' once complete, and then 'OK'. The waveform should be displayed in the main window.
In the record dialogue, you can adjust the recording quality by changing the sampling rate. The default rate of 16000 samples per second with 16-bit resolution has been chosen to be most useful for the production of speech spectrograms. Not all PCs support acquisition at 16000 samples per second. You may find it necessary to record at 22050 samples/second or at 11025 samples/second. UCLEnhance does not support recording using old 8-bit resolution cards although it can load 8-bit waveforms recorded by other applications.
Displays
Waveform
A waveform is a graph of signal amplitude (on the vertical axis) against time (on the horizontal axis). Conventionally, the zero line is taken to mean no input: in terms of a microphone this would imply that the sound pressure at the microphone was the same as atmospheric pressure. Positive and negative excursions can then be considered pressure fluctuations above and below atmospheric pressure. For speech signals these pressure fluctuations are very small, typically less than +/- 1/1000000 of atmospheric pressure. The amplitude scale used on waveform displays merely records the size of the quantised amplitude values captured by the Analogue-to-Digital converter in the PC. These have a maximum range of -32,768 to +32,767. If you observe values close to these on the display, it is likely that the input signal is overloaded.
Wideband spectrogram
A spectrogram is a display of the frequency content of a signal drawn so that the energy content in each frequency region and time is displayed on a grey scale. The horizontal axis of the spectrogram is time, and the picture shows how the signal develops and changes over time. The vertical axis of the spectrogram is frequency and it provides an analysis of the signal into different frequency regions. You can think of each of these regions as comprising a particular kind of building block of the signal. If a building block is present in the signal at a particular time then a dark region will be shown at the frequency of the building block and the time of the event. Thus a spectrogram shows which and how much of each building block is present at each time in the signal. The building blocks are, in fact, nothing more than sinusoidal waveforms (pure tones) occuring with particular repetition frequencies. Thus the spectrogram of a pure tone at 1000Hz will consist of a horizontal black line at 1000Hz on the frequency axis. Such a signal only contains a single type of building block: a sinusoidal signal at 1000Hz.
Wideband spectrograms use coarse-grained regions on the frequency axis. This has two useful effects: firstly it means that the temporal aspects of the signal can be made clear - we can see the individual larynx closures as vertical striations on a wide band spectrogram; secondly it means that the effect of the vocal tract resonances (called formants) can be seen clearly as black bars between the striations - the resonances carry on vibrating even after the larynx pulse has passed though the vocal tract. The bandwidth for the wideband display is fixed at 300Hz.
Statistics
These statistics are displayed by the option Signal/Statistics:
- Number samples. A digital signal is comprised of a number of discrete amplitude values, representing the amplitude of the original signal at small equally-spaced intervals of time. This value tells you the total number of amplitude samples.
- Sample rate. This tells you how many sampling intervals fit into one second; or in other words how many samples would make up a recording lasting one second.
- Range. This tells you the size of the smallest and the largest sample. Note that the program stores waveforms in a 16-bit binary format which naturally limits the amplitude to a maximum range of -32768 to +32767.
- RMS level. This value is an estimate of the average power in the non-silent portions of the signal. This is not the same as the average power over the whole signal since that would change if significant amounts of silence were added or removed from the recording. This method divides the signal up into 25ms chunks or "windows" and discards windows which are more than 50dB below the window with the largest power. Average power is then calculated over the remaining windows. Power is measured with respect to a sinusoidal signal of maximum amplitude (i.e. peak amplitude of 32767 units) and hence is usually negative.
- Speech level. This value is an estimate of the average power in the parts of the signal where speech is present. As for the RMS level above, this method discards quiet regions from the calculation. It also measures power with respect to a maximal sinusoidal signal. The method is an implementation by Laurie Moye (now at 2020Speech Ltd) of CCITT Recommendation ITU-T-P56, which was derived from UK Post Office Speech Voltmeter No.6. It is made available under the following licence arrangement:
* (C) Crown Copyright $Date: 1998/07/09 16:13:00 * * This SV6 Speech Voltmeter Computer Program (sv6.c, sv6.h and * sv6_funcs.c) is subject to Copyright owned by the United Kingdom * Secretary of State for Defence acting throught the Defence * Evaluation and Research Agency (DERA). It is made available to * Recipients with a royalty-free licence for its use, reproduction, * transfer to other parties and amendment for any purposes not * excluding product development provided that any such use et cetera * shall be deemed to be acceptance of the following conditions:- * * (1) Recipients of original or amended forms of it shall ensure * that this Notice is reproduced upon any copies or amended versions * of it; * * (2) Any amended version of it shall be clearly marked to show both * the nature of and the organisation responsible for the relevant * amendment or amendments; * * (3) Its onward transfer from a Recipient in original or amended * form to any other party shall be free of any charge or other * obligation to provide a benefit in return and shall be deemed to be * that party's acceptance of these conditions; * * (4) Recipients of original or amended forms of it accept that DERA * gives no warranty or assurance as to its quality or suitability for * any purpose or the like of results obtained using it and DERA * accepts no liability whatsoever in relation to any use to which it * may be put.
- Speech activity. This value reports what fraction of the signal was considered to be speech by the Speech Level calculation.
Enhancement
Automatic Gain Control
The Automatic Gain Control (AGC) enhancement functions modify the overall amplitude of the signal. There are two AGC options:
- RMS Level. The RMS (root mean square) level automatic gain control modifies the overall level of the signal such that the RMS level of the signal is approximately -20dB below the maximum signal level that can be recorded in a 16-bit linearly quantised signal. The RMS level is based on the average power in the non-silent regions of the signal, see statistics.
- Speech Level. The Speech Level automatic gain control modifies the overall level of the signal such that the Speech Level of the signal is approximately -20dB below the maximum signal level. Speech Level is based on the average power in the regions of the signal where speech is present, see statistics.
Amplitude Compression
The Amplitude Compression enhancement function modifies the relative amplitudes of different regions of the signal. It tends to make the signal more "even" in amplitude by increasing the amplitude of quiet regions while leaving louder regions unchanged.
This implementation divides the signal into short overlapping windows of about 30ms and applies a "µ-law" amplitude mapping to each window as shown in the diagram below (not to scale).
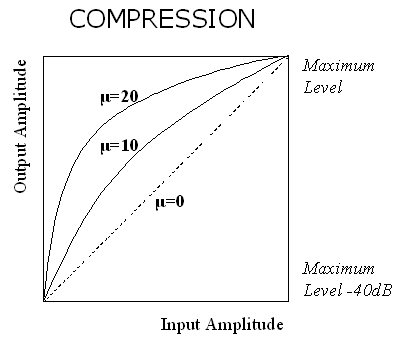
If the amplitude of a window is within 40dB of the loudest window then its amplitude is modified according to the compression function. Larger values of µ increase the gain given to quieter regions. Larger values tend to make the signal more even in amplitude. The maximum amplitude of the signal is barely changed.
There is evidence that a small amount of compression increases the intelligibility of a clean speech signal when presented in background noise.
Spectral Subtraction
The Spectral Subtraction enhancement function modifies the spectral content of the signal and can be used to reduce the quantity of background noise present in a signal. The enhancement procedure works in two stages: in stage 1 it tries to determine which aspects of the signal are due to backgound noise: it does this by finding what energy is present in the quietest regions of the signal. In stage 2 it subtracts the energy due to the background noise from every part of the signal: it does this by calculating the spectrum of short overlapping windows of the signal and by scaling the spectral magnitudes before converting back to the time domain.
By default this implementation is fairly conservative in the amount of noise it removes. The subtraction degree factor linearly scales the default amount of the background noise estimate subtracted, with 100=default. Over large values of this factor will lead to distortion.
While there is evidence that spectral subtraction makes noisy speech signals more pleasant to listen to, there is little evidence that it causes any gain in intelligibility.
Phonetic Enhancement
The Phonetic Enhancment function modifies the relative amplitude of different portions of the signal. Unlike the other methods, this function is specifically designed to be sensitive to the phonetic content of speech signals. It can selectively boost the amplitude of regions of the signal known to be important for the differentiation of phonetic categories. The categories are as follows:
- Bursts. Bursts are short regions of turbulent noise caused by the sudden release of pressure that occurs in sounds like /b,d,g,p,t,k/. Bursts are known to be very important in the discrimination of (for example) /b/ from /m/ or /b/ from /d/.
- Fricatives. Fricatives are extended regions of turbulent noise caused by constrictions in the vocal tract that occur in such sounds as /f,v,s,z,h/. Fricatives are often much quieter than the vowel portions of speech and can be masked by background noise.
- Nasals. Nasals are regions of voiced speech signals that arise when the oral cavity is blocked and the soft palate lowered so that the noise of larynx vibration escape through the nose. This occurs in such sounds as /m,n/. Since the oral cavity is closed, nasal sounds are often much quieter that the vowel portions of speech.
- Transitions. Transition regions occur when the articulators are moving rapidly, often from a constricted position to a vowel position or vice versa. These transitions, occurring as they do at the edges of vowels, are perceptually very important in helping the listener discriminate between different consonantal articulations occurring adjacent to the vowel. Thus they are more important than the steady-state vowel portion.
This implementation of phonetic enhancement only allows simple control over which regions should be boosted in amplitude. There is an automatic procedure based on a broad-class phonetic recognition system that determines the location of vowels, fricatives, nasals and gaps. From these, potential enhancement regions are identified: bursts (BUR), fricatives (FRC), nasals (NAS), vowel onset transitions (ONS) and vowel offset transitions (OFS). According to the options chosen these regions of the signal are increased in amplitude.
Experiments at UCL have shown that phonetically-selective enhancement can increase the intelligibility of clean speech signals presented to listeners in noise. However care must be taken not to increase the overall loudness of the signal in these experiments. We suggest that an automatic gain control is also selected when phonetic enhancement is used. If AGC is not used then you cannot be sure that increases in intelligibility are due to enhancement or just to a general increase in signal to noise.
Want to learn more?
Publications
These publications may be downloaded from the Enhance project web site at http://www.enhance.phon.ucl.ac.uk/.
- Hazan, V. and Simpson, A. (1998) The effect of cue-enhancement on the intelligibility of nonsense word and sentence materials presented in noise. Speech Communication, 24, 211-226.
- Hazan, V., Simpson, A. and Huckvale, M. (1998) Enhancement techniques to improve the intelligibility of consonants in noise : Speaker and listener effects. Proceedings of International Conference of Speech and Language Processing, Sydney, Australia, December 1998.
- Huckvale, M. (1996) A syntactic pattern recognition method for the automatic location of potential enhancement regions in running speech. Speech, Hearing and Language 1996 , working papers from Phonetics and Linguistics, UCL.
- Hazan, V. and Simpson, A. (1996) Enhancing information-rich regions of natural VCV and sentence materials presented in noise. Proceedings ICSLP Philadelphia.
- Hazan, V. and Simpson, A. (1996) Cue-enhancement strategies for natural VCV and sentence materials presented in noise. Speech, Hearing and Language 1996 , working papers from Phonetics and Linguistics, UCL.
- Hazan, V. and Simpson, A. (1995) Enhancing the perceptual salience of information-rich regions of natural intervocalic consonants. Proceedings Eurospeech 95, Madrid.
Speech and Hearing
If you find the study of speech interesting and would like to know more, why not visit the Internet Institute of Speech and Hearing at www.speechandhearing.net ? There you will find tutorials, reference material, laboratory experiments and contact details of professional organisations.
Bug reports
Please send suggestions for improvements and reports of program faults to SFS@phon.ucl.ac.uk.
Please note that we are unable to provide help with the use of this program.
Copyright
UCLEnhance is not public domain software, its intellectual property is owned by Mark Huckvale, University College London. However UCLEnhance may be used and copied without charge as long as the program and help file remain unmodified and continue to carry this copyright notice. Please contact the author for other licensing arrangements. UCLEnhance carries no warranty of any kind, you use it at your own risk.